
 It is always good to meet les mongueurs de perl de France. As we say in French “ils sont vachement sympas”. At the Journees Perl I learnt about the latest developments of Perl 6 which hopefully you will soon be able to try or at least read about them. What did they talk about? Rakudo, JVM, MoarVM, Parrot, Moose, Moe, Niecza, Perlito and much more. It just reminded me of an anecdote when O’Reilly was looking for a book cover design in the mid eighties. The designer was briefed and was told about the titles of the books O’Reilly was publishing – Emacs, vi, lex and yacc, unix etc., her reaction was “It’s a jungle out there” and allegedly that’s how our animal books were created. That is the way I feel about all the new stuff I have heard during this conference.
It is always good to meet les mongueurs de perl de France. As we say in French “ils sont vachement sympas”. At the Journees Perl I learnt about the latest developments of Perl 6 which hopefully you will soon be able to try or at least read about them. What did they talk about? Rakudo, JVM, MoarVM, Parrot, Moose, Moe, Niecza, Perlito and much more. It just reminded me of an anecdote when O’Reilly was looking for a book cover design in the mid eighties. The designer was briefed and was told about the titles of the books O’Reilly was publishing – Emacs, vi, lex and yacc, unix etc., her reaction was “It’s a jungle out there” and allegedly that’s how our animal books were created. That is the way I feel about all the new stuff I have heard during this conference.
Some of the talks included:
- What’s new in Perl 5.18 – Sébastien Aperghis-Tramoni
- Functional Programming for Perl Mongers – Marc Chantreux
- Yet another Perl 6 Interpreter – François Perrad
- Angel’s Prompt – details of implementation – Olivier Mengué
- Wordle in Perl – Yves Agostini
- Sympa – David Verdin
I am hoping that I will be able to publish Liz Mattijsen’s “Perl’s Diaspora – Should we fear the future?” very soon.
 The organization team created some great posters and provided some of the best food. Unfortunately due to the rail strike not many delegates made it to Nancy. It is a shame that the team was not rewarded for such a great job.
The organization team created some great posters and provided some of the best food. Unfortunately due to the rail strike not many delegates made it to Nancy. It is a shame that the team was not rewarded for such a great job.

During Maker Faire UK last month, Josette met with Helen Schell, an artist drawing inspiration from space exploration and the cosmos. Helen combines art with astrophysics, working with scientists to create her truly unique pieces.
Helen’s portfolio is diverse and prolific. When we saw her at the Faire, she was exhibiting her eye-catching Dazzle Dress – a sculpted ball-gown made of high-vis materials, ‘fit for the Queen of the Moon’ (pictured left). She talked to Josette about rocketry, colonising the moon, and her artwork:
I make work inspired by rocketry, time travel and the extraordinary features of the Universe. Through mixed media art installations and large paintings, I produce work using astrophysics, and collaborate with scientists primarily from Durham University. These artworks are physical objects shown in transformed spaces as site-specific exhibitions, preferably in non-gallery venues. This line of work started in 2007 and led me into an exciting environment where science and art thrive together.
 In 2010, Helen was the artist in residence at Durham University’s Ogden Centre for Fundamental Physics. Whilst there, she was inspired by real science, and invented fictional journeys across space. She created a Space-Time Laboratory which contained pseudo-objects like space souvenirs, protective eyewear, and The Kathedra, a Space-Time Throne. She has since exhibited the 11th Dimension, an installation made up of 11,000 glass lenses which has been shown in Durham Cathedral and NewBridge Project Open Studios. Recently, she has become increasingly interested in the Moon and the idea of its colonisation:
In 2010, Helen was the artist in residence at Durham University’s Ogden Centre for Fundamental Physics. Whilst there, she was inspired by real science, and invented fictional journeys across space. She created a Space-Time Laboratory which contained pseudo-objects like space souvenirs, protective eyewear, and The Kathedra, a Space-Time Throne. She has since exhibited the 11th Dimension, an installation made up of 11,000 glass lenses which has been shown in Durham Cathedral and NewBridge Project Open Studios. Recently, she has become increasingly interested in the Moon and the idea of its colonisation:
Over the last year, I have focused on the Moon, which has become the target for space exploration again, and now there are plans to colonise it. This project started last summer on an art residency at Meltdowns, where I set up a Lunar Laboratory. This included research, communication and creating artworks. Whilst there, I attended Kent University’s Space School and ran a Lunar Habitat workshop for children, and I ironically got to hold real Moon-rock whilst creating fake Moon-rock! Since then, I have developed the lunar theme by creating a new Moon Rocket painting (see detail below), 10m high, inspired by the Apollo/Saturn rocket. As a STEM ambassador, I run a series of workshops for children entitled ‘Make it to the Moon‘, for a generation who may well witness this event, and I also run Smart Materials costume workshops.

This project led to Helen becoming ‘Maker in Residence’ at The Centre for Life in Newcastle, the home of Maker Faire UK. What’s next for Helen?
In 2012, I collaborated with Durham University’s NETPark on Undress:Redress, a Smart Materials costume residency and exhibition, designing and making UN-Dress (pictured on the left), the Rocket Dress and the Dazzle Dress, three flamboyant ball-gowns. Two of the dresses are dissolvable and will be filmed whilst they disintegrate in water. My latest project is Moon-shot: First Woman on the Moon, which is an exhibition of large works inventing future lunar missions. These works include the Moon Rocket, a Lunar Space Station, a dynamic Full Moon, and quasi lunar artefacts.

Keep up to date with Helen’s latest projects by visiting her page on The Newbridge Project.
On the 7th of June this year, 150 entrepreneurs will gather at the Barbican Conference Centre to attend the only Lean Analytics Workshop taking place in London.
The organiser is a tech start-up based in Shoreditch, called Geckoboard. Geckoboard chose to host the event after publishing a study earlier this year in which more than 300 start-ups around the world were surveyed.

Their research revealed that most start-ups struggle when it comes to making sense of data, and acting upon it. 49% of the respondents do not feel confident about the metrics they are currently monitoring. Based on analysis of data gathered in the report, this group is also less likely to have processes in place to ensure that data is understood and acted upon. There is a clear need for entrepreneurs to understand how to make better-informed decisions.
 Paul Joyce, Geckoboard CEO, was already familiar with the authors of Lean Analytics, and seeing the relevance of the book to the current challenges that start-ups are facing, organizing an event with authors in London was an straightforward decision.
Paul Joyce, Geckoboard CEO, was already familiar with the authors of Lean Analytics, and seeing the relevance of the book to the current challenges that start-ups are facing, organizing an event with authors in London was an straightforward decision.
The Lean Analytics workshop is targeted to entrepreneurs, founders, growth hackers and analytics professionals in the UK, especially in the tech industry. The workshop will cover the foundations of Lean Analytics, in combination with live case studies where early stage start-ups will be invited on stage to share their data challenges with the rest of the audience.
This event is expected to be intense, and to leave participants with a wide variety of techniques and best practices that can be applied straight away.
In a world where data is becoming one of the most valuable resources, understanding how to make informed decision can make a huge difference.
If you would like to take part, you can book your ticket here.
 On 13-14 June, Stockholm will be the best place in Europe to discuss Multi-core, Big Data, Cloud, Embedded, NoSQL, Mobile and the Future of the Web. The Erlang User Conference 2013 features over 40 speakers including top experts such as the inventors of Erlang Mike Williams, Robert Virding and Joe Armstrong, the author of Yaws and Mnesia Claes Wikström, O’Reilly authors Bruce Tate and Zachary Kessin, distributed systems expert Steve Vinoski, embedded expert Ulf Wiger and many more. They will present, evaluate and illustrate with case studies tools, frameworks and experiences in building massively concurrent distributed systems with Erlang. Companies represented at the event are Campanja, Ericsson, Klarna, Basho, Erlang Solutions, Tail-f, Spillgames, and prestigious research centers like the Swedish Institute of Computing Science and Uppsala University.
On 13-14 June, Stockholm will be the best place in Europe to discuss Multi-core, Big Data, Cloud, Embedded, NoSQL, Mobile and the Future of the Web. The Erlang User Conference 2013 features over 40 speakers including top experts such as the inventors of Erlang Mike Williams, Robert Virding and Joe Armstrong, the author of Yaws and Mnesia Claes Wikström, O’Reilly authors Bruce Tate and Zachary Kessin, distributed systems expert Steve Vinoski, embedded expert Ulf Wiger and many more. They will present, evaluate and illustrate with case studies tools, frameworks and experiences in building massively concurrent distributed systems with Erlang. Companies represented at the event are Campanja, Ericsson, Klarna, Basho, Erlang Solutions, Tail-f, Spillgames, and prestigious research centers like the Swedish Institute of Computing Science and Uppsala University.
Take advantage of a 25% discount off the price of the conference when you register with the code OREILLY here.
With RESTful services becoming ever more popular as a way of sharing information between systems, and PHP still widely adopted as the language of the web, these two technologies are regular bedfellows. As always with PHP, there’s more than one way to work with a RESTful service, but a great option is to use streams. The streams interface is more elegant than PHP’s clunky cURL extension, and is always included in PHP. Best of all, this is stream handling, so if a response is very large it can be processed in bite-sized chunks. Let’s look at some examples of consuming a real REST service with PHP streams. We’ll use GitHub as an example since they have a good RESTful service, great documentation, and are widely known.
Starting Simple with a GET Request
Let’s begin by grabbing a list of the gists associated with my GitHub account (a gist is like a pastebin, if you haven’t seen one before):
| <?php | |
| ini_set('user_agent', "PHP"); // github requires this | |
| $api = 'https://api.github.com'; | |
| $url = $api . '/users/lornajane/gists'; | |
| // make the request | |
| $response = file_get_contents($url); | |
| // check we got something back before decoding | |
| if(false !== $response) { | |
| $gists = json_decode($response, true); | |
| } // otherwise something went wrong |
 by
by
The response is an array of the publicly-visible gists on my account, each represented by an array and including information about the user that created them (me). The documentation for working with gists using GitHub’s API is here:http://developer.github.com/v3/gists/ The file_get_contents() stream wrapper is by far the easiest and quickest way to grab content from a URL in PHP. There is so much more we can do with it though!
Write Operations with Stream Contexts
All the stream functions in PHP have support for a $context argument, which allows us to send more information about the stream we’re sending. For an HTTP or HTTPS stream like the ones in these examples, that means we can set the headers, verbs and body to send with our request. To try this out, we’ll create a gist on GitHub, and do so we need to be logged in. In API terms, that means we need to identify ourself when we make the request, and since GitHub uses Oauth2, we can just send a header containing a valid access token that I acquired by following their excellentation documentation which you can find at http://developer.github.com/v3/#authentication Our next request also needs to send some body data as well as auth information; this is the content for the new gist which we’ll POST to Github. We can set the verb, the body data, and the headers we need all in the context of the stream. Take a look at this example:
| <?php | |
| include "github-creds.php"; // sets $access_token | |
| ini_set('user_agent', "PHP"); // github requires this | |
| $api = 'https://api.github.com'; | |
| $url = $api . '/gists'; // no user info because we're sending auth | |
| // prepare the body data | |
| $data = json_encode(array( | |
| 'description' => 'Inspiring Poetry', | |
| 'public' => 'true', | |
| 'files' => array( | |
| 'poem.txt' => array( | |
| 'content' => 'If I had the time, I\'d make a rhyme' | |
| ) | |
| ) | |
| )); | |
| // set up the request context | |
| $options = ["http" => [ | |
| "method" => "POST", | |
| "header" => ["Authorization: token " . $access_token, | |
| "Content-Type: application/json"], | |
| "content" => $data | |
| ]]; | |
| $context = stream_context_create($options); | |
| // make the request | |
| $response = file_get_contents($url, false, $context); |
First of all I’m pulling in my access token from a separate include file (to avoid oversharing or having to revoke tokens). Then we set the URL and assemble the data we want to send. This will be different on different systems but I’m working off GitHub’s documentation for creating a gist: http://developer.github.com/v3/gists/#create-a-gist. Setting the context is probably the trickiest bit, and even then you can see the pieces clearly. Set that this should be a POST request, then give some extra headers; we set the Content-Type because we’re sending JSON in the body of this request (the GitHub API works only in JSON), and the Authorization header contains our access token so GitHub knows who we are. Finally we set the data we prepared earlier as the content for the stream. When the gist is created successfully, the response will give full information about this gist and its new URL, along with a 201 status code to tell you it was created (inspect this by checking the $http_response_header> variable). If the first code sample was run again now, we’d see a new entry appear in our list, and it’s also visible on the website: [gists.png] We can work with gists and other types of API data programmatically, and PHP is a great tool for this.
Going Beyond GET and POST
The streams solution is a more friendly interface than the more traditional PHP curl, and it’s equally powerful as we’ve seen in the examples so far. It can be used to make requests using any HTTP verb, the only requirement is that both client and server should understand it. For example, if we wanted to update the gist that we just created, then we’d make a request to GitHub using the PATCH verb. PATCH isn’t supported everywhere, but GitHub have adopted it as a great way of updating records, including partial records, and this is becoming more popular in RESTful services. Here’s an example of how we might do that using the stream context:
| <?php | |
| include "github-creds.php"; // sets $access_token | |
| ini_set('user_agent', "PHP"); // github requires this | |
| $api = 'https://api.github.com'; | |
| $url = $api . '/gists/5501496'; // URL of the specific gist | |
| // prepare the body data | |
| $data = json_encode(array( | |
| 'description' => 'Rather Lame Poetry' | |
| )); | |
| // set up the request context | |
| $options = ["http" => [ | |
| "method" => "PATCH", | |
| "header" => ["Authorization: token " . $access_token, | |
| "Content-Type: application/json"], | |
| "content" => $data | |
| ]]; | |
| $context = stream_context_create($options); | |
| // make the request | |
| $response = file_get_contents($url, false, $context); | |
| echo $response; | |
| print_r(json_decode($response)); | |
| print_r($http_response_header); |
The changes are accepted by GitHub and the response contains the updated gist, in this case the script just changes the description field.
PHP and Streams
The streams extension is core to PHP and so it will always be available, making it a great choice for code that needs to be deployed to a number of platforms. The interface is simple and elegant, so as a developer it’s easy to work with while at the same time being completely configurable, allowing even the more complex kinds of requests as we saw here. Best of all, if you’re dealing with very large responses, you can handle them in segments rather than loading the entire response into memory, as well as getting all the other features of streams such as being able to filter them as needed. There are many ways to make HTTP requests from PHP but streams are definitely one of the best, combining power with flexibility.
Lorna Jane Mitchell is a web development consultant and trainer from Leeds in the UK, specialising in open source technologies, data-related problems, and APIs. She is also an open source project lead, regular conference speaker, prolific blogger, and author of PHP Web Services, published May 2013 by O’Reilly.
In this interview, which completes a trilogy on implementations of Perl 6, we talk to Flávio Glock about Perlito, the compiler collection that implements a subset of Perl 5 and Perl 6. It is a very interesting discussion that revolves around topics like parsing, bootstraping, VM’s, optimizations and much more.
Flávio Glock Soibelmann has developed several CPAN modules for the DateTime Dashboard. He is currently one of the developers of Perl and Perlito is his main current project.

Perlito is an intriguing piece of technology capable of compiling Perl 5 or Perl 6 programs into various backends, currently including JavaScript, Python, Ruby and Go. It may be extended to other backends as the project is very active.
Perlito’s potential is very exciting as it is open to hacking extensions and backends, while also acts as a platform for experimenting with language semantics, optimizations and code generation. Aside from that research and develop aspect, it also bears a practical face for end-users, as Perl in the browser demonstrates.
Looking into the future and in the case that Perlito manages to implement the full language set, then it maybe would spearhead the reshaping of Perl’s landscape.
NV: So Flávio, you work for Booking.com in the code optimization sector?
FG: Yes, for about 5 years now.
NV: What is this area of activity occupied with – code refactoring, experimenting with algorithms, tweaking Perl’s internals?
FG: It is mostly about identifying bottlenecks – and then fixing; we have some people tweaking Perl’s internals too, but this is not my area.
NV: So what is the motivation behind Perlito?
FG: Perlito started as a bootstrapping compiler for Pugs – we wanted to rewrite Pugs in Perl6. It was called “mini-perl6” at that time. The plan was to support both Haskell and Perl5 as backends
I think the regex compiler for Pugs still uses mini-perl6:
http://search.cpan.org/dist/Pugs-Compiler-Rule/
This is the mini-perl6 source code for the module:
http://cpansearch.perl.org/src/FGLOCK/Pugs-Compiler-Rule-0.37/examples/Grammar.grammar
NV: Can you provide a short high level overview of Perlito’s underlying architecture or how does it work behind the scenes?
FG: Perlito has 2 compilers – a Perl6 compiler written in Perl6, and a Perl5 compiler written in Perl5
This is an old picture, but this is still pretty much how the Perlito compilers work:
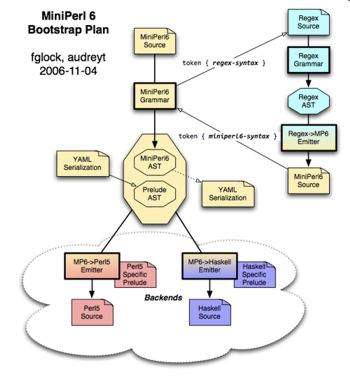
Perlito
There is a grammar, which transforms the input text into a data tree (AST), and there is an emitter, which transforms the tree into machine-readable code. Other modules are provided to handle other more complex cases.
In Perlito5, the grammar is implemented as Perl5 modules which you an see here:
http://github.com/fglock/Perlito/tree/master/src5/lib/Perlito5/Grammar
The internal structure of Perlito6 is more “monolithic”, it needs some refactoring. There is a third component, which is the Runtime.This is where the backend-specific features (and workarounds) are implemented – for example, the CORE module for javascript:
https://github.com/fglock/Perlito/blob/master/src5/lib/Perlito5/Javascript2/CORE.pm
NV: Perlito’s definition is : “a compiler collection that implements a subset of Perl5 and Perl6 “. Why a subset, what is left out and what cannot be done in comparison to the full-set?
FG: The plan is to support the full language, but this is not possible yet. Each backend supports a set of features; for example this file is a description for Perl5-in-Javascript.
Javascript does not support sleep(), for example. On virtual machines that do automated garbage collection, reference counting is hard and it is important to support DESTROY and automatic closing of file handles. You can work around in most cases, but there is usually an impact on performance
There are several steps in the compilation. Perlito parses the code, and then emits code that will be executed by a specific virtual machine. In some cases, there is no easy way to generate specific instructions, it is a limitation of the backend
I’m currently working on the x64 backend, this is very low level and should have fewer or no limitations.
NV: From all the backends the show stealer is the Javascript backend which allows controlling the browser through Perl! What is the generated Javascript capable of, how far can it go?
FG: You can try it out at :
http://perlcabal.org/~fglock/perlito5.html
There is also a Perl6 version, but that is quite behind, because I’ve spent most of the past year working on the Perl5 compiler.
There are a few features specific to the js backend, such as
JS::inline(‘document.getElementById(“print-result”).value’)
This comes from the Pugs-js implementation.
The compiler supports perl objects, simple regexes, as well as more “advanced” features like tied arrays. There is also a more complete js backend, the ‘js3’ version – which emulates more closely Perl5 but that comes at a performance price.
The version that you see online has a reasonable balance between functionality and performance and is good enough to compile the Perlito source code to Javascript;that is how perlito5.js is built:
http://perlcabal.org/~fglock/perlito5.js
NV: As an industry insider working for one of the biggest Perl5 advocates (if not the biggest) do you think that an organization of such a size would someday consider switching from Perl5 to Perl6?
When would the setting be mature enough for such a switch?
FG: It will eventually happen. At some point people will use it for one-off scripts, and then somebody will use it on a cronjob, but it will not replace Perl5 in this environment – it will instead compete with alternate languages, like Go.
NV: So what are Perlito’s potential uses for developers and end-users alike?
FG: The main product for end-users are the Perl-js compilers. They can be integrated in other projects, like azawawi++ did with the Farabi web-based IDE.
For developers there are a lot of possibilities. Perlito is pretty open to hacking, there are no hard coded limits
NV: Finally, what are your expectations for the future?
FG: The Perlito5::X64::Assembler package should allow for building an efficient, Perl-specific environment. At some point, if this becomes the main development platform for Perlito, we don’t need to work around virtual machine limitations anymore.
The other side of the Perlito development is to allow better Perl5/Perl6 inter-operation;there is already a Perl6-to-Perl5 compiler in CPAN :
http://search.cpan.org/dist/v6/
This is based on Perlito6. The plan is to finish the Perl5-to-Perl6 compiler, that would work about the same way as v6.pm.
For the full interview please follow Perlito – An Interview With Flávio Glock
Nikos Vaggalis has a BSc in Computer Science and a MSc in Interactive Multimedia. He works as a Software Engineer/Database Application Developer and codes in Perl and C#.
NoSQL databases are increasingly popular and when we decided which database to bind first in the Opa framework, we chose the famous NoSQL MongoDB database, that some say is “the greatest mug company ever”. But at the same time, we kept having lots of request about the support of more classical SQL databases.
![]() Opa just reached 1.1.1 today, and the little version increase brings in support for the Postgres database. This article explains how to move back from NoSQL to SQL.
Opa just reached 1.1.1 today, and the little version increase brings in support for the Postgres database. This article explains how to move back from NoSQL to SQL.
Hello Migration
Suppose you have a minimal Opa app that uses the database:
import stdlib.themes.bootstrap
database mydb {
int /counter
}
function page(){
<h1 id="msg">Hello</h1>
<a onclick={ function(_) {
/mydb/counter++;
#msg = <div>Thank you, user number {/mydb/counter}</div>
}}>Click me</a>
}
Server.start(
Server.http,
{~page, title: "Database counter"}
)By default, when you generate the Node.js app with
opa counter.opaand launch it with
./counter.jsit will run on MongoDB and displays a counter which increments itself when clicked.
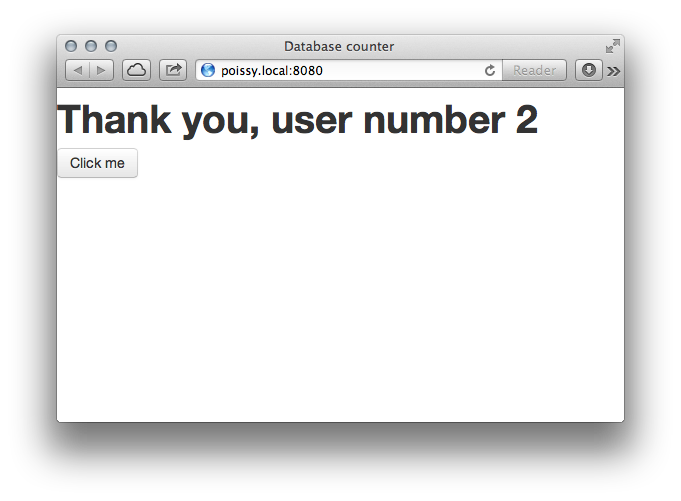
To use Postgres as database backend instead of MongoDB, you just need to edit the database declaration to specify to the Opa compiler to use Postgres:
database mydb @postgres {
int /counter
}The app does not yet generate the ‘mydb’ database automatically, so before running the application, you need to create the database
psql -c "CREATE DATABASE mydb"Then just run your app normally:
./counter.jsTo specify database credentials you can run instead
./counter.js --postgres-auth:mydb user:password[a] --postgres-default-host:mydb locahost:5432Digging into Complex Stuff
In our former example case, the database is limited to a single integer… But things get nicer when we store more complex datastructures such as lists, maps (the dictionaries in Python), records or any combination of them. Let’s generalize the previous example to have one counter per page, and create a homepage that aggregates a few statistics.
Let’s first redefine the database declaration to have one counter by page:
database mydb[b][c] @postgres {
{string page, int counter, Date.date last} /counters[{page}]
}In the above snippet, we declare a database set, for which page is the primary key. Switching from MongoDB to Postgres is again just about adding the @postgres keyword.
The next is to update the view, according to the new database declaration. The database update code becomes:
{ page: name, counter++, last: Date.now() };that naturally sets the page name, with last seen updated to the current time and increments the page views. The database update is performed with a single request. The view itself is:
function page(name) {
<h1 id="msg">Page {name}</h1>
<a onclick={function(_) {
/mydb/counters[page == name] <- { page: name, counter++, last: Date.now() };
#msg = <div>{ /mydb/counters[page == name]/counter } page views</div>
}}>Click me</a>
}
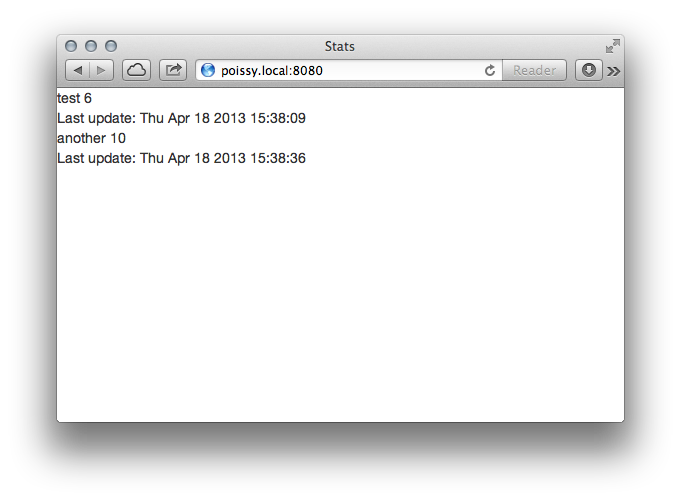
Let’s add another view to display a few stats. Basically, we want to show all pages sorted by last update where the counter is greater than 5. To specify the query, we use Opa’s comprehensive data syntax:
function stats() {
iter = DbSet.iterator(/mydb/counters[counter > 5; order +last])
Iter.fold(function(item, acc) {
acc <+>
<div><span>{item.page}</span> <span>{item.counter}</span></div>
<div>Last update: {Date.to_string(item.last)}</div>
}, iter, <></>)
}
Finally, we write the controller using an URL dispatch:
function dispatch(url) {
match (url) {
case {path: {nil} ... } :
{ Resource.page("Stats", stats()) };
case {path: path ...} :
title = String.concat("::", path)
{ Resource.page(title, page(title)) };
}
}
Server.start(
Server.http,
{~dispatch}
)In this example app, migrating from MongoDB to Postgres (or the contrary) requires almost no code change. If you want to come back to MongoDb just edit the database declaration by removing @postgres annotations or replace by @mongo. Even better, you can mix both database engines in the same application if you want.
In further releases of Opa, we will probably take runtime definitions into separate definitions and support a few platforms-as-a-service straight out of the box.
How it works: DbGen
The magic behind the previous example has a name: The “DbGen” automation layer. Unlike most ORM layers, DbGen as its name suggest is basically a code generation layer. DbGen generates queries statically, in a safe way that prevents code injections, among other runtime errors.
As Opa is a strongly statically typed technology, DbGen uses a database schema which includes type information from the program to validate queries statically. The information-rich schema is used to create the NoSQL data structure or the corresponding SQL schema. In our previous example, the schema declaration:
database mydb @postgres {
{string page, int counter, Date.date last} /counters[{page}]
}generates for Postgres a SQL table named counters that contains 3 columns, where the primary key is page:
CREATE TABLE counters(page TEXT, counter INT8, last INT8, PRIMARY KEY(page))Note that the generated SQL code is clean and the database structure can be easily used by humans, for instance in conjunction with admin tools. Opa also generates stubs to access the database. For example, the following data access
/mydb/counters[page == name]is compiled as a pre-compiled Postgres query:
SELECT * FROM counters
WHERE page == $1It’s efficient, and clean.
Wrap Up
Try it for yourself! Opa 1.1.1 which now supports both MongoDB and Postgres is available from the Opa portal. The source is available on GitHub.

All resources to get you started are available from the portal, and ask your questions on StackOverflow or our own forum. The best reference on Opa is the O’Reilly book, available from Amazon or directly from O’Reilly.
A press release from our friends at DoES Liverpool. If you are unable to go to Internet World, DoES Liverpool will be at Maker Faire UK, Newcastle on 27th and 28th April.

You might think that “things” have always been connected to the internet. Computers, mobile phones, even printers have been connected for years. A lot of the current talk and investment in Internet of Things is large sensor networks and taking information from our environment. What we at DoES Liverpool like to think of when we talk about the Internet of Things is a whole lot more personal and unexpected. How about a bubble machine that blows bubbles when people mention you or your business on Twitter? Or perhaps a clock or dial that instead of showing time or statistics shows where someone is? These are just two of the ideas that members of the DoES Liverpool community will be bringing to Internet World this month.
But first, what is DoES Liverpool? We are many things. We are an online community of creative and often tech savvy people, of tech startups and “makers”. DoES Liverpool is also a physical space. It provides a co-working office space for members of the community to hot desk from or to take a permanent desk. There’s also a shared workshop with lots of equipment available for use; traditional tools such as soldering irons and band-saws to the more modern digital fabrication equipment like the laser cutter and 3D printers. We also hold regular events on many topics from specific programming languages like Python and Clojure through to more business focussed events like Lean Liverpool and Saturday Startup Club. We have a great community coming up with some wonderful ideas, and we’re looking forward to showing some of these to you at Internet World 2013.

Adrian McEwen has been putting things on the Internet for many years. He led the team who developed the first full web browser for a mobile phone, and his code (he’s slightly ashamed to admit) made it onto the Amstrad Emailer. He was recently described as an IoT pioneer by Kevin Ashton, the person who coined the term “Internet of Things” in the first place! Adrian will be bringing two of his IoT inventions to Internet World. Bubblino, the aforementioned twitter activated bubble blowing machine, was actually one of his first IoT projects but is well loved at conferences around the UK and has now been sold to various people in the UK and Europe. The Acker’s Bell was a more recent commision to provide Liverpool Startup ScraperWikiwith a bell that would chime each time they made a sale. The mounting for the bell was designed and laser cut in DoES Liverpool with Adrian developing the software and electronics. Usually living in ScraperWiki’s office in Liverpool the Acker’s Bell will be visiting London for you to see at Internet World 2013
With another DoES Liverpool co-founder, Hakim Cassimally, Adrian has spent the last year writing the definitive IoT book – Designing for the Internet of Things. Both Adrian and Hakim will be available to discuss their book and IoT in general, and of course you can pre-order the book on Amazon!

Inspired by the clock owned by the Weasley family in the Harry Potter books, the WhereDial provides a delightful way to make a personal connection with a family member or friend. The WhereDial is made from laser cut plywood or colourful plastic and features a list of location categories around the dial. Through the cloud based location aggregator –MapMe.At – the WhereDial can retrieve a person’s location from FourSquare, Google Latitude and a variety of other services. It then rotates the dial to show where the person is. It’s a great device for people who are less comfortable using mobile phones and computers but is also a really handy glanceable object that fits nicely on the desk of a technophile too. The WhereDial was designed and is built in Liverpool by John McKerrell, also a co-founder of DoES Liverpool.

Perhaps saving the best for last, the final headline item that we’ll be bringing to Internet World 2013 is the Good Night Lamp. Darling of CES and Gadget Show Live, these lamps have a superstar team behind them. They are the brainchild of Alexandra Deshamps-Sonsino, previously a co-founder of smart product design studio Tinker London and the organiser of the monthly Internet of Things meetups in London. She launched the Good Night Lamp as a startup a year ago by committing to taking a booth at CES; 10 months of development later and with a live Kickstarter campaign garnering much publicity she took CES by storm. Her team includes our own Adrian McEwen as CTO; John Nussey as Head of Products and interior designer & architect Konstantinos Chalaris as Lead Designer.
We really hope you will enjoy our exhibition and go away inspired, potentially with some ideas for an IoT product of your own! DoES Liverpool is all about inspiring people to start interesting businesses and while our focus is in Liverpool, we know that IoT is going to take off around the world!
As you know, at O’Reilly we are very proud of the animals displayed on the covers of our books. Our animals are so famous that the public often refer to them instead of the title of the book. We have, to name a few:
- the tarsier book (Learning the vi Editor)

- the llama book (Learning Perl)
- the camel book (Programming Perl)
- the polar bear book (Information Architecture for the World Wide Web)
- the Rhino book (JavaScript: The Definitive Guide)
etc.
At conferences, our animals are very often the opening topic of conversation at the booth. A question I am always asked is “What are you going to do when you run out of animals?” or “Why do you use this animal?” I listen to some very funny conversations –
– Why do you use a bat on the sendmail book?
– because sendmail sends you batty.
or
– Why do you use a camel on Programming Perl?
– because a camel goes a long way.
Right or wrong, it does not really matter. What matters is that people are talking about our books as a great source of knowledge. But… what happens to the animals? So please listen to Edie Freedman, the O’Reilly Creative Director.
“When I designed the first Animal covers for O’Reilly, I had no idea how popular the animals would become; 25 years later, the brand continues to flourish. Unfortunately, the same is not true of the real-life animals whose images appear on many of the book covers.”
Our books have been there to help you achieve your dream career but during that time, gloom has descended on our animals, and many are now critically endangered. Conservationists are in desperate need of people with your tech expertise and O’Reilly hope to help by putting you in touch with them. Please read on and find a way to help our animals so that our future society can benefit from them.
There are many ways to get involved:
- making donations to conservation organizations
- volunteering your time in the field and/or bringing your technical expertise to bear on the problems
- using technological expertise to track populations, detect poachers and help the conservation organizations achieve their goals.
On The O’Reilly Animals, you will find all you need to help.
Please follow us on Twitter, @OReillyAnimals, retweet and spread the word!
Press Release from the Organisers of Thinking Digital
![]()
Thinking Digital Announces Speaker Line up for 2013 (Monday 18th March)
21st -23rd May 2013 sees the 6th annual staging of the Thinking Digital Conference at the Sage Gateshead Music Centre. Over the years Thinking Digital has built a reputation for attracting the best thinkers and speakers from the around the world to Tyneside.
For the 2013 Conference, our first speaker announcement includes..
- Aza Raskin – the co-founder of the Massive Health startup that was recently acquired by Jawbone. Aza was formerly the design lead for Mozilla. His father, Jef, started the Macintosh project at Apple in 1979.
- Mike Bracken – formerly the Digital Director of Guardian News & Media, Mike was named the Director of Digital for the Cabinet Office in 2011. He leads the Government Digital Service (GDS) which aims to make the government’s digital presence much easier to find and use. His team has led the launch of the GOV.UK portal.
- Jack Andraka – is a 16 year old scientist who won the 2012 Intel Science and Engineering Fair for creating a pancreatic cancer test that is estimated to be 168 times faster, 26,000 times less expensive and potentially almost 100% accurate. He’s spoken most recently at the TED Conference in Long Beach, California.
- Maggie Philbin – the former presenter of the BBC’s Tomorrow’s World and current presenter on BBC One’s Bang Goes the Theory, Maggie is a very well known face for UK science and technology enthusiasts. What’s less well known is that Maggie’s a Director of TeenTech which she co-founded with IOD Chairman, Chris Robson. TeenTech is busy inspiring Tomorrow’s Generation of young scientists, engineers and techies.
- Horace Dediu – was declared “the new king of Apple analysts” in 2010 by Fortune Magazine. While most of his competition come from richly resourced firms such as Morgan Stanley or Credit Suisse, Horace’s analysis is completely independent and self-financed. Horace’s Asymco blogs and charts on the smartphone and personal technology market have built him a huge readership.
- Karen Dillon – was until recently the Editor of the Harvard Business Review. She left to co-author How to Measure Your Life alongside management guru Clayton Christensen.
- Ed Parsons – was the very first CTO of the Ordnance Survey in its 200 year history. He is now helping define the future for Google Maps as their Geospatial Technologist.
- Dr. Sue Black – rose to fame helping spread the word to save successfully Bletchley Park, home of the world’s first programmable computer and the epicentre of the UK’s WWII codebreaking efforts. Currently, she is very active in helping encourage more women into technology.
- Aral Balkan – a well known and liked experience designer who was recognised by Microsoft and .Net Magazine as one of the top speakers of 2012.
- Alexa Meade – an American artist who has innovated visually stunning technique for painting directly onto live models in 3D space to make them look like 2D paintings.
- Graham Hughes – this British filmmaker recently completed a four year journey to every country in the world without ever once resorting to an airplane. His exploits have earned him a show on the National Geographic channel and a place in the Guinness Book of World Records.
The full roster of 25 announced speakers is available here.
Tickets will remain priced at £225+vat until Thursday, 28th March. More information.
The Founder & Director of Thinking Digital 2013, Herb Kim, said, “Thinking Digital has built a reputation for attracting the world’s best thinkers and speakers. We are genuinely blessed to have such a roster of rock stars make the journey from around the globe to Tyneside in May for Thinking Digital 2013. We look forward to creating a fabulous experience for the entire Thinking Digital community.”